AI时代,媒体内容价值或将重估
过去几年,大模型的参数规模呈几何倍数增加。
OpenAI 2018年发布GPT-1时,参数量仅为1.17亿,2年后的GPT-3将参数规模扩大千倍,达到1750亿。到2021年 Google发布Switch Transformer,参数量已经拉高至万亿规模。OpenAI虽未公布GPT-4的参数量,但从业内爆料信息来看,GPT-4参数规模或达1.8万亿,训练所需的数据集更是高达13万亿Token。
人类对于数据的渴求从未像今天这般强烈。7月,加州大学伯克利分校计算机科学教授斯图尔特?罗素发出警告,ChatGPT等人工智能驱动的机器人可能很快就会 “耗尽宇宙中的文本”。专注于AI领域的研究机构Epoch则预测,至多3 年,机器学习将耗尽所有高质量语言数据集。
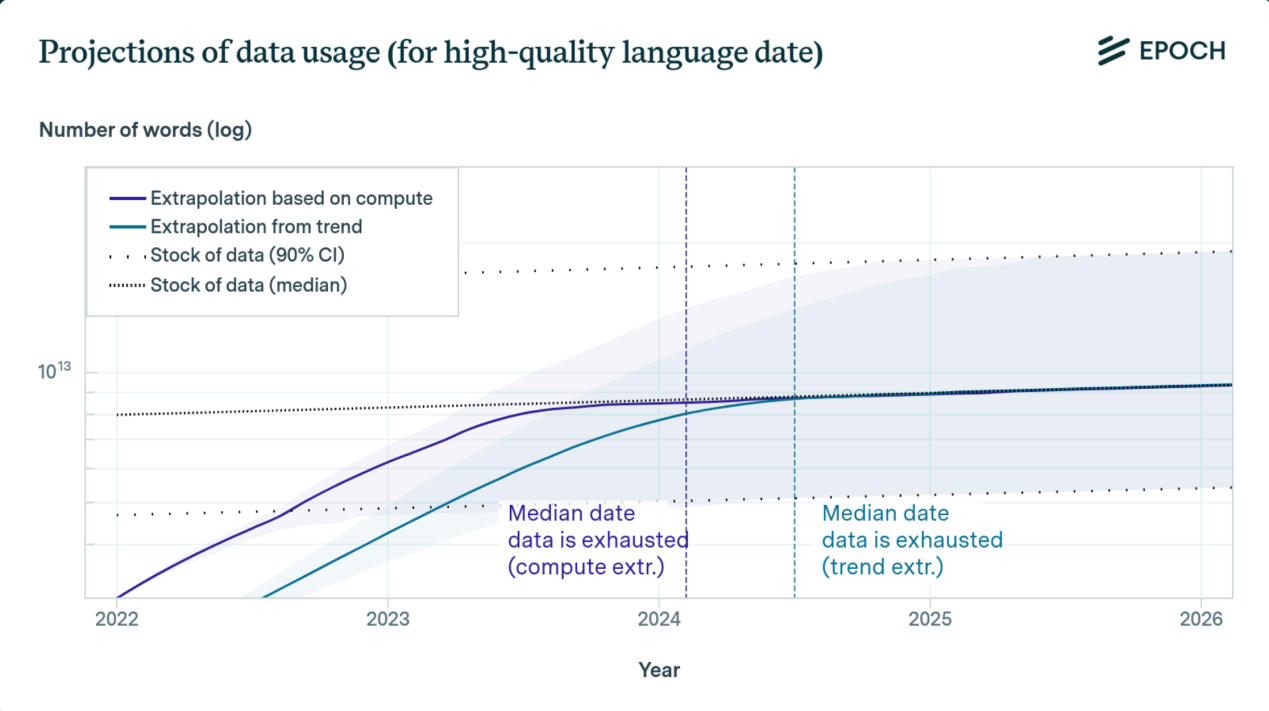
其中,中文数据更是处于劣势。W3Techs按日更新的世界互联网语言排名中,中文网站占比仅为1.4% ,仅比越南语稍高,而英语为53%。目前世界上通用的50亿大模型数据训练集中,中文语料占比也只有1.3%。

“很多人担心算力,但真正的问题是数据。”香港科技大学(广州)协理副校长、人工智能学域主任 熊辉近日参加凤凰卫视举办的大模型数据研讨沙龙时说,整体的中文数据在整个人类知识的数据体系中仅占很小一部分,中国大模型如何真正做到跨语言体系、跨文化体系,在构建高价值、高质量、全方位的数据集上仍然面临较大挑战。

越来越多的分析机构将高质量数据纳入影响大模型发展的核心因素。中信智库在其发布的《人工智能十大趋势》中指出,未来,一个模型的好坏20% 由算法决定,80% 由数据质量决定。“高质量数据将成为提升模型性能的关键。”
但问题是,高质量数据从何而来?
01媒体数据或成为AI训练的有益补充
OpenAI最早训练GPT模型使用的数据大多来自互联网上的公开数据,比如维基百科词条、出版书籍以及杂志期刊等,但其中占比最多的数据还是来自于网站爬虫。比如GPT-3就爬取了来自社交平台Reddit约 50GB的数据,以及来自网页数据库Common Crawl约 570GB的数据。
这些数据并非到手即用,来自互联网的数据庞杂无序,仍需经过大量的数据标注与清洗工作才可用于训练AI。此前外媒报道称,OpenAI雇佣了来自肯尼亚、乌干达及印度的外包员工来为他们过滤互联网上的有害信息,一度引发市场争议。
AI训练所用数据的合规性也越来越引起广泛关注。今年,Reddit、推特等社交平台相继收紧政策以阻碍第三方获取平台数据,纽约时报、路透社在内的多家媒体机构被爆出已屏蔽来自OpenAI的网络爬虫程序。针对AI滥用数据的抗议与诉讼不断发生,反对者包括作家、编剧、艺术家以及程序员群体等。
为了保证高质量数据的供给,OpenAI最早的尝试是与新闻媒体合作。7月份,美联社与OpenAI达成合作,授权OpenAI使用旗下生产的部分新闻内容训练大模型,文本素材最早可追溯至1985年。OpenAI的首席运营官布拉德·莱特卡普称,“美联社的反馈意见以及OpenAI对其高质量、真实文本存档的访问将有助于提高OpenAI系统的能力和实用性。”
外界对这次合作的评价多持正面态度。一些分析认为新闻媒体的内容具备真实且客观中立的特质,将有助于提升大模型效果,并减少训练时长。在预训练阶段采用更多的媒体数据,也将遏制早期AI容易产生的偏见、仇恨等负面内容。
华泰证券在其发布的调研报告中表示,高质量数据将是未来AI大模型竞争的关键要素,而未来专业及垂直内容平台有望成为国内优质中文数据集的重要来源。
众多电视媒体中,最早意识到媒体数据对于AI训练价值的,并且积极主动拥抱AI浪潮、寻求改变和突破的或许是凤凰卫视。凤凰卫视日前推出了旗下的AI数据业务,并发布了首批百万轮次的“中文访谈对话数据集”和10万问答对的“正向价值对齐数据集”。
凤凰卫视融媒体研发副总经理冯伟说,他们最早在去年开始尝试将平台内容进行数据集的整理。诱因之一是他们在与高校及科技公司的接触中,发现高质量的中文语料十分匮乏。在经过了几个月的走访和调研后,他们认为,高质量数据语料库将是AI时代承载中华文化的新载体,因此决定下场参与中文高质量数据集的构建。

这一动作受到不少行业公司的欢迎。微博COO、新浪移动CEO、新浪AI媒体研究院院长王巍在接受媒体采访时呼吁,希望更多的媒体机构加入到中文数据集的建设中。“它为AI技术提供了丰富、多样的数据源,有助于提升AI模型对中华文化的理解。”

参加凤凰卫视数据研讨沙龙的华为云EI产品部部长尤鹏表示,华为希望和凤凰卫视一起共建数据黑土地,共同探索产业界自下而上的数据合作路径和商业模式,共同构建大模型的“数据-算力-商业”飞轮,推动数据产业发展。
据介绍,凤凰卫视近期推出的数据业务包括两部分,一是高质量的数据集市,即以凤凰内容为基础构建的数据集产品;二是与数据集打通的一站式AI训练平台。AI训练平台将与数据集市打通,并提供一系列以数据为中心的服务,可大幅降低数据处理与AI训练的门槛和成本。
海外除了美联社与OpenAI的合作,近期也有消息显示包括纽约时报、卫报、新闻集团等媒体机构均在与科技公司讨论合作事宜。从这个角度上说,凤凰卫视这次下场或许为众多媒体机构提供了一个可借鉴的样板。
02凤凰特色的AI数据集
目前,中文大模型训练所用的数据集大致可分为以下几类:
1. 平台自有数据。如百度、阿里、腾讯等互联网巨头凭借其自身生态积累的大量数据资产。
2. 国内开源数据。多由高校、科研院所及科技公司联合发布。如清华大学和北京智源人工智能研究院联合发布的WuDaoMM数据集、中国人民大学发布的COCO-CN数据集等。
3. 海外开源数据。包括英文数据集产品及网站爬虫内容等。如维基百科、Common Crawl等网站数据,以及大量来自政府机构、高校及开源组织发布的数据集产品。相较来说,海外数据集产品质量及丰富程度更高。
其中,真正来自专业媒体的高质量语料数据少之又少。负责凤凰卫视数据集产品的冯伟认为,他们推出的数据集产品根植于凤凰本身内容,试图将内容本身特色嫁接于数据集产品之上。
特色之一是这家媒体多年来一直标榜的全球视野。公开资料显示,凤凰卫视在全球拥有60个记者站,能带来更为及时和准确的一手新闻资讯。更及时、准确的信息有利于提升AI模型的理解能力。
“所有的数据开发都必须更加及时、快速和顺应时代。”凤凰卫视执行副总裁兼运营总裁李奇说,人工智能的到来加速了人类数据的演变和构建,领军企业正在不遗余力地获取最新的数据,以确保大模型的知识不会落后。
GPT-3.5的信息只停留在2022年 1月,而最新的GPT-4 Turbo提升到了今年4 月。马斯克的人工智能公司xAI最新发布的大模型Grok则可以实时访问X 平台(Twitter)的数据,极具时效性,这让它毫无障碍地理解当下最新的热门话题。

时效性正是媒体数据之于其他传统数据集产品最显著的优势。媒体内容产品包括文本、视频、语音等多模态内容,无论是其信息的丰富度、时效性乃至后续的更新,都是传统数据产品无法比拟的。事实上,凤凰卫视在发布首批数据集产品时,着重强调的一点就是他们将会定期更新数据集内容,以保证内容的时效性。
“作为覆盖台、网、屏、刊、端的全媒体平台,凤凰卫视每天产生大量的多模态内容,这些可持续的内容数据为我们开发数据集产品提供了天然的优质基础。”冯伟说。
不过,凤凰卫视更为人津津乐道的或许是旗下如《问答神州》《名人面对面》等王牌访谈节目,以及时下较为稀缺的、如财经论坛、零碳使命、世界文化论坛等顶级峰会中的精英人物思想。据介绍,凤凰卫视发布的首批“中文访谈对话数据集”,就是基于旗下访谈类节目生成,规模达百万轮次。

(凤凰卫视《问答神州》特别节目——智能时代,未来已来。对话中国工程院院士、国家新一代人工智能战略咨询委员会组长潘云鹤;鹏城实验室主任、中国工程院院士高文;世界工程组织联合会主席龚克;中国工程院院士、信息内容安全技术国家工程实验室主任方滨兴)
访谈是与当下以ChatGPT为代表的聊天型人工智能最为贴近的交流方式。冯伟介绍称,他们的访谈数据集最大的特点是连续对话,平均轮次超30轮;且话题多样,涉及时事热点、精英人物、传统文化乃至经济科技等多个领域。
另一特点是整体内容来源于真实访谈,可以最直观地展现人与人之间的对话模式,而这一直以来都是生成式AI训练的难点之一。
此前,人工智能公司的数据清洗工作大多仍是数据标注等基础性劳动,但随着ChatGPT的火爆,人工智能公司们不得不投入更多的人力来训练AI的回答更像人类。
据报道,OpenAI在训练GPT-4时招募了大量的员工来“指导”AI,来使它的回答更接近人类的期望。这被业内称之为“基于人类反馈的强化学习”(RLHF)。当下,国内的科技公司们也开始密集招募大量具有一定知识背景的AI训练师,要求本科甚至硕士学历,月薪可达4万。
据冯伟介绍,媒体内容的语料化是一项极具挑战性的工作,其中涉及包括自然语言处理、计算机视觉及音频识别等多种AI技术的运用。在数据的完善度上,他们针对每个话题均附有相关上下文信息,包括人物介绍、话题背景等。涉及的相关概念及政策等知识,他们也基于知识图谱完成了知识补充。
目前,凤凰卫视发布的首批访谈对话数据集仍以文本类为主,他们计划此后还将推出多模态方向的数据集产品。据透露,凤凰卫视计划在明年分三批发布更多高质量数据集,包括面向财经领域的评论数据集、面向视频内容理解领域的视频问答数据集、面向数字人领域的谈话动作数据集和语音合成数据集等。

此外,他们还计划与相关数据伙伴共同构建具有高价值和稀缺性的高质量数据集,包括华语图文对数据集、华语书籍数据集和网络流行语数据集。
03大模型的“正向价值”
媒体数据的另一优势在于媒体内容本身的客观中立,或将有助于减少AI模型的负面内容。
此前,已有多个国家及地区公布了人工智能监管法案。欧盟在今年6 月投票通过了《人工智能法案》,要求任何应用于就业、边境管制和教育等“高风险”用例的人工智能都必须遵守一系列安全要求,包括风险评估、确保透明度和提交日志记录。对于ChatGPT等生成式人工智能,则需披露训练模型时使用了哪些有版权的数据。
国内8 月正式发布的《生成式人工智能服务管理办法》,其中明确提出在算法设计、训练数据选择、模型生成和优化、提供服务等过程中,采取有效措施防止产生民族、信仰、国别、地域、性别、年龄、职业、健康等歧视。
美国总统拜登10月份签署通过的人工智能监管法令,要求美国最强人工智能系统的研发人员需与政府分享其安全测试结果及其他关键信息,同时建立检测人工智能生成内容和验证官方内容的标准和最佳实践,以帮助民众防范人工智能驱动的欺诈。
11月初,在英国召开的首届全球人工智能安全峰会上,包括中国在内的与会国共同发布了《布莱切利宣言》,与会国同意协力打造一个国际性的前沿人工智能安全科学研究网络,以加深对人工智能风险的理解。
“这是第一次以国际共识的方式承认并正视人工智能的副作用。”李奇认为,这标志着这个快速新兴的技术已经真正来到每个人的身边。

业内常用人工智能价值对齐来形容人工智能与人类价值观是否相符。ChatGPT诞生之初,尚且会生成涵盖种族歧视、灭绝人类的内容。随着过去一年大模型的飞速发展,更多业内人士认为价值对齐将是衡量大模型能力的重要指标。
“一个能力很强大的AI模型可以做到很多,但同时也承担着巨大的风险。”上海交通大学副教授刘鹏飞在一场关于大模型价值对齐的研讨会上表示,缺乏对齐的大模型不仅会生成大量虚假甚至有害的信息,在高阶应用领域更会产生巨大的危险隐患。
凤凰卫视发布的首批数据集中即包含了“正向价值对齐数据集”。据介绍,该数据集构建基于凤凰与权威学术团队的研究成果,由凤凰卫视专业内容团队人工撰写而成,规模达十万个问答对。在每个问答对中,均包含了正向和负向回答,可提升模型在正向价值对齐方面的鲁棒性。

构建人工智能的正向价值并非易事。腾讯研究院秘书长张钦坤在一次活动上表示,价值对齐将成为AI产品的重要竞争力,因为这一目标需要多种技术与治理措施的结合,如何使监督、理解、设计AI模型的能力与模型本身的复杂性同步发展也需着重考虑。
不过至少,作为新闻媒体,凤凰卫视所构建的“正向价值对齐数据集”试图迈出第一步。
凤凰卫视执行副总裁兼运营总裁李奇说,凤凰卫视作为一个立足香港、背靠内地、面向全球发展的国际媒体,也将是人工智能时代的积极参与者,期望发挥凤凰媒体平台优势,为产业界建立一个共建共享的数据平台,共同推进人工智能的快速发展。
注:文章来源/芒信源,本文为作者独立观点,不代表亿邦动力立场。
分享一个国内免费使用GPT4.0的AI智能问答工具:智答专家。支持AI文本、作图、语音、Sora视频。无需魔法,亲测有效,点击访问
标签:AI时代
来源:admin
发布时间:2023-11-16 19:08

