Llamaberry来了,和OpenAI o1思维链模型一样的效果,它是开源的
有研究者宣称已经成功复现/开发出了与 ο1性能差不多的推理技术,并且还不止一个!
Llamaberry:教会 AI 像聪明人一样思考
Llamaberry 的提出者是 Martin Bowling。他开发的项目包括 RAGMiner.dev 和 Replit;其中前者可以帮助用户毫不费力地将网站转换成 Markdown、XML 或 JSON 等格式以便 RAG 和 LLM 应用使用,而后者则是一个使用 AI 将想法变成代码的项目。
Llamaberry 的核心思路是使用思维链(CoT)来实现推理。这个名字自然源自代表 o1模型的 Strawberry(草莓)。
HuggingFace地址:https://huggingface.co/spaces/martinbowling/Llamaberry
什么是思维链?Bowling 在博客中打了个比方:「思维链推理就像是给 AI 一个笔记本来展示其工作过程。其中不仅仅是简单地给出答案,而是会带领我们经历其思维过程。」
Llamaberry 能教会 AI 透彻地思考,就像是一位人类专家攻克难题时那样。
具体来说,Llamaberry 是一个多轮思维链推理系统的实现,其基于运行在 Groq 上的 Llama3.170B 模型。
多轮推理是关键
多轮推理,顾名思义,就是让模型在给出答案之前进行多步思考,而不是一步给出答案。打个比方,这就像是看一位大厨从备菜到完成摆盘一步步地完成一道精美菜肴,而不是直接微波加热预制菜。
举个示例:
第1轮:AI 先尝试解决当前问题。
第2轮:AI 回顾第一次尝试并尽力改进或优化其思维过程。
第3轮:再进行一轮反思和改进。
综合结果:最后,将所有这些思考综合到一起,得到一个连贯且合理的答案。
下面展示了这个多轮过程的示意图:
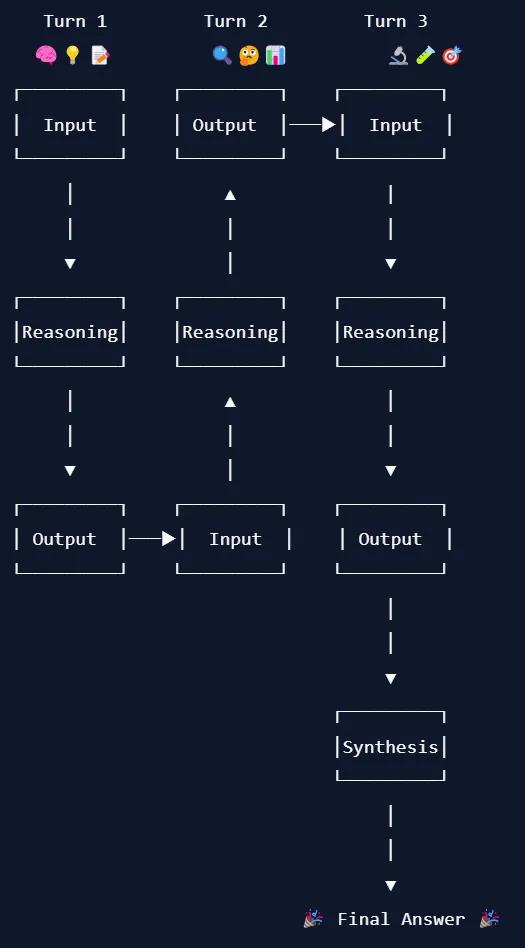
可以看到,前一轮的输出会成为后一轮的输入,从而让 AI 可在每个阶段不断完善其思维。最后,所有这些思考会凝练成一个合理的最终答案。就像看着一枚莓果逐渐成熟!
如何实现
下面将深入 Llamaberry 的实现细节。
1.设置舞台
首先,我们需要为 AI 助手设置一些基本规则,代码如下:
initial_system_prompt="""YouareanAIassistantcapableofdetailed,step-by-stepthinking.Whenpresentedwithaquestionorproblem,breakdownyourthoughtprocessintoclear,logicalsteps.Foreachstep,explainyourreasoning.Concludewithafinalanswer.Usethefollowingmarkdownstructure:
这就是提供给 AI 大厨的菜谱。它知道需要逐步分解其思考过程并解释每个步骤,并且以 Markdown 格式将它们显示出来。
2.思考过程
在每一轮推理中,都需要让 AI 对问题进行思考。但在第一轮结束后,还需要求它思考之前已经思考过的东西。这就像问朋友,「嘿,还记得你之前说过什么吗?让我们再想一想。」
下面是每一轮的生成方式:
asyncdefgenerate_turn(query:str,previous_turns:list=None)->str:
该函数是多轮推理的核心。它决定我们是在第一轮还是在后续轮,并以此构建提示词。对于后续轮,它会将之前所有推理轮都包含在上下文中,让 AI 可以基于之前的思考进行构建。
3.综合结果
经过三轮思考之后,再让 AI 检视其所有思考并得出一个合理的最终答案。这就像是让专家讨论问题,然后编写最终报告。
asyncdefsynthesize_turns(query:str,turns:list)->str:turns_text="\n\n".join([f"Turn{i+1}:\n{turn}"fori,turninenumerate(turns)])messages=[{"role":"system","content":synthesis_prompt},{"role":"user","content":f"OriginalQuery:{query}\n\nTurnsofReasoning:\n{turns_text}"}]returnawaitcall_llm(messages)这个综合步骤至关重要,是 AI 综合所有思考内容凝练出最终答案的一步。
单轮推理 vs 多轮推理
Martin Bowling 在其博客中简单比较了单轮和多轮推理。
这里他采用了一个简单示例,即询问 AI:「人工智能对就业市场有什么潜在影响?」
单轮推理:
AI:Artificialintelligencewilllikelyhavesignificantimpactsonthejobmarket,including:
使用 Llamaberry 执行多轮推理:
第1轮:
AI:Let'sapproachthisstep-by-step:
第2轮:
AI:Let'srefineourthinking:
第3轮:
AI:Let'sdelvedeeper:
综合答案:
AI:Aftercarefulconsiderationacrossmultipleturnsofreasoning,wecansynthesizeourthoughtsonthepotentialimpactsofartificialintelligenceonthejobmarket:
可以看到,多轮方法能实现更加精细、全面的分析。这能从多个角度考虑问题,优化其思考,最后得到更加深思熟虑和全面详细的答案。
Bowling 表示,这样的多轮推理在思考深度、自我提升、透明度、灵活性等方面都有巨大优势,同时其还采用了 Markdown 格式,使其结果更容易阅读和用于后续流程。
因此,这种技术可让 AI 进入更多实际应用场景,比如医疗诊断、法律分析、科学研究、商业策略、教育。当然,在使用 Llamaberry 等多轮推理系统时,也需要注意它们的局限和潜在的道德伦理问题,比如偏见、计算成本、过度依赖和隐私问题。
如何使用 Llamaberry?
Llamaberry 也很容易使用,点击几下就能拥有你自己的多轮推理系统。步骤如下:
前往 Replit,点击该链接获取 Llamaberry 模板:https://replit.com/@MartinBowling/Llamaberry-Powered-By-Groq?v=1
创建模板分支:点击 Fork 按钮创建你自己的 Llamaberry 项目副本。
获取你的 Groq API Key:注册 Groq 账户,获取 API Key。
设置环境:在你的分支 Replit 项目中,找到「Secrets」选项卡。添加一个新密钥,密钥为 GROQ_API_KEY,值是你的 Groq API 密钥。
运行项目:单击 Replit 界面顶部的 Run 按钮。这将启动 Llamaberry 应用。
开始实验:应用运行起来后,你将看到一个 Gradio 界面。你可以在其中输入问题并查看 Llamaberry 多轮推理的实际效果!并且输出是简洁漂亮的 Markdown 格式!
了解了 Llamaberry,下面来看另一个号称实现了类 o1推理链的项目:g1。
g1:实现类似 ο1的推理链
g1这个项目来自 Benjamin Klieger,他是 Groq 的一位研究者。也因此,g1同样基于 Groq,并且其也使用了 Llama3.170b 模型。
不同于 Llamaberry 使用的多轮思维链推理,g1的策略是角色扮演、思维链提示 、格式化以及另一些提示技巧。并且,g1开源了。
项目地址:https://github.com/bklieger-groq/g1

开发者宣称 g1有70% 的时间能成功数出 Strawberry 中有多少个 R,同时无需任何微调或少样本技术。下面是其一次执行过程:

开发者 Klieger 表示,g1和 ο1一样能让 LLM 有能力「思考」和解决之前的领先模型难以应对的逻辑问题。但不同之处在于,g1会大方地展示所有推理 token。同时,他也强调了 g1和 ο1在技术上的差异,其中后者使用了大规模强化学习来执行思维链推理。而 g1则是通过发掘提示词工程的潜力来帮助 LLM 解决简单的逻辑问题,让现有的开源模型也能受益于动态推理链和优化般的探索界面。
g1的工作方式
由 Llama3.170b 支持的 g1会创建一种动态的思维链。
在每个步骤中,LLM 可以选择是继续进行另一个推理步骤,还是提供最终答案。每个步骤都有标题,并且对用户可见。
系统提示词中还会包含给 LLM 的提示。其提示策略如下:
YouareanexpertAIassistantthatexplainsyourreasoningstepbystep.Foreachstep,provideatitlethatdescribeswhatyou'redoinginthatstep,alongwiththecontent.Decideifyouneedanothersteporifyou'rereadytogivethefinalanswer.RespondinJSONformatwith'title','content',and'next_action'(either'continue'or'final_answer')keys.USEASMANYREASONINGSTEPSASPOSSIBLE.ATLEAST3.BEAWAREOFYOURLIMITATIONSASANLLMANDWHATYOUCANANDCANNOTDO.INYOURREASONING,INCLUDEEXPLORATIONOFALTERNATIVEANSWERS.CONSIDERYOUMAYBEWRONG,ANDIFYOUAREWRONGINYOURREASONING,WHEREITWOULDBE.FULLYTESTALLOTHERPOSSIBILITIES.YOUCANBEWRONG.WHENYOUSAYYOUARERE-EXAMINING,ACTUALLYRE-EXAMINE,ANDUSEANOTHERAPPROACHTODOSO.DONOTJUSTSAYYOUARERE-EXAMINING.USEATLEAST3METHODSTODERIVETHEANSWER.USEBESTPRACTICES.
对这些提示词的详细解释请参阅原项目的 Prompt Breakdown 一节。这里就不赘述了,仅给出几个示例,比如可以在提示词中加入「include exploration of alternative answers」(探索其它答案)和「use at least3methods to derive the answer」(使用至少三种方法来得出答案)。
这样一来,通过组合思维链以及尝试多种方法、探索其它答案、质疑之前草拟的解答、考虑 LLM 的局限性等策略,就能显著提升 LLM 的推理能力。
在数 Strawberry 中有多少个 R 这个经典问题上,无需任何训练,g1就能帮助 Llama3.170b 达到约70% 的准确度(n=10, How many Rs are in strawberry?)。而如果不使用提示技术,Llama3.170b 的准确率为0%,ChatGPT-4o 的也只有30%。
下面展示了另一个示例:0.9和0.11哪个更大?
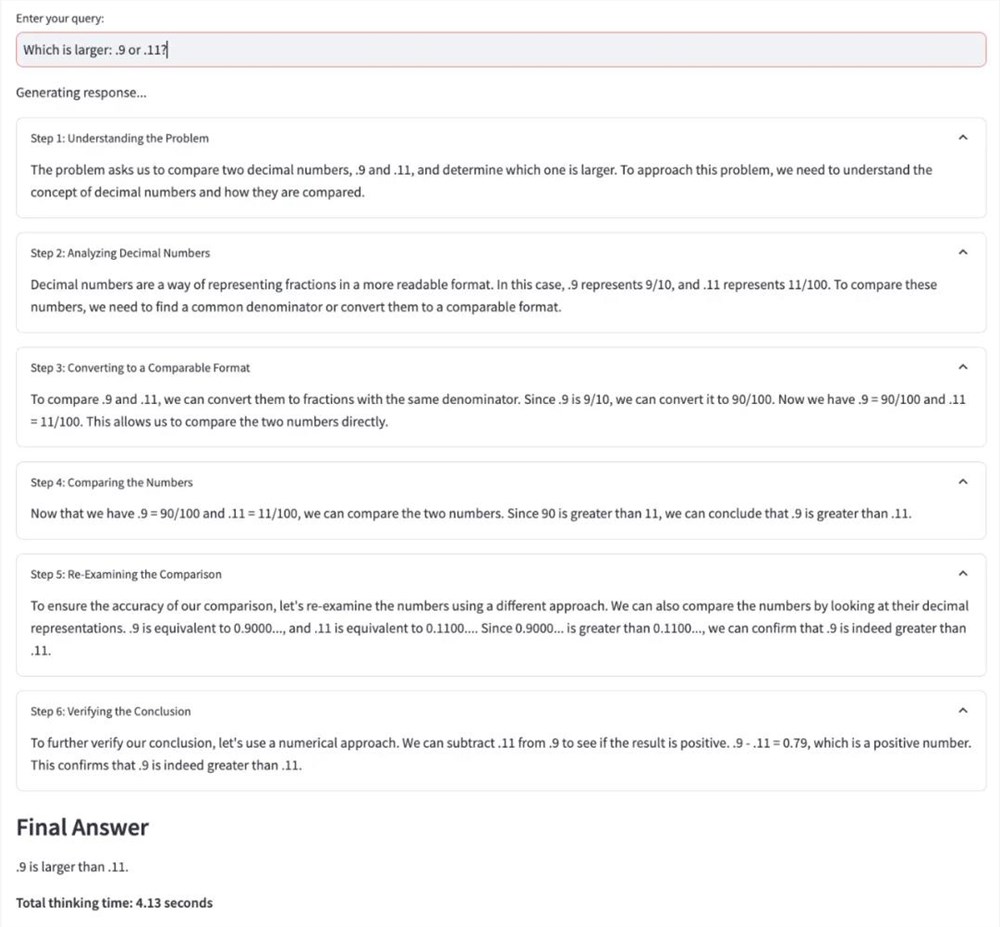
详细的安装过程和代码请参阅原项目。
最后,顺便一提,另有开发者发布了 g1的分支版 Mult1,该版本的一大改进是可使用多个 AI 提供商来创建类似 o1的推理链,感兴趣的读者可访问:https://github.com/tcsenpai/multi1
分享一个国内免费使用GPT4.0的AI智能问答工具:智答专家。支持AI文本、作图、语音、Sora视频。无需魔法,亲测有效,点击访问
标签:Llamaberry
来源:智答专家
发布时间:2024-09-18 13:32

