人人都可以用ChatGPT!英伟达chat with RTX 安装和使用完全攻略!私有化部署本地大模型!
如何傻瓜式部署本地离线大模型?
本地的、离线的、吃自己数据的、不用投硬币的大模型怎么用上?英伟达突然放出了一个工具:chatwithRTX,非常良心,直接下载,大小有点感人,35.1G,下完解压,然后抬起APM300的右手双击安装。
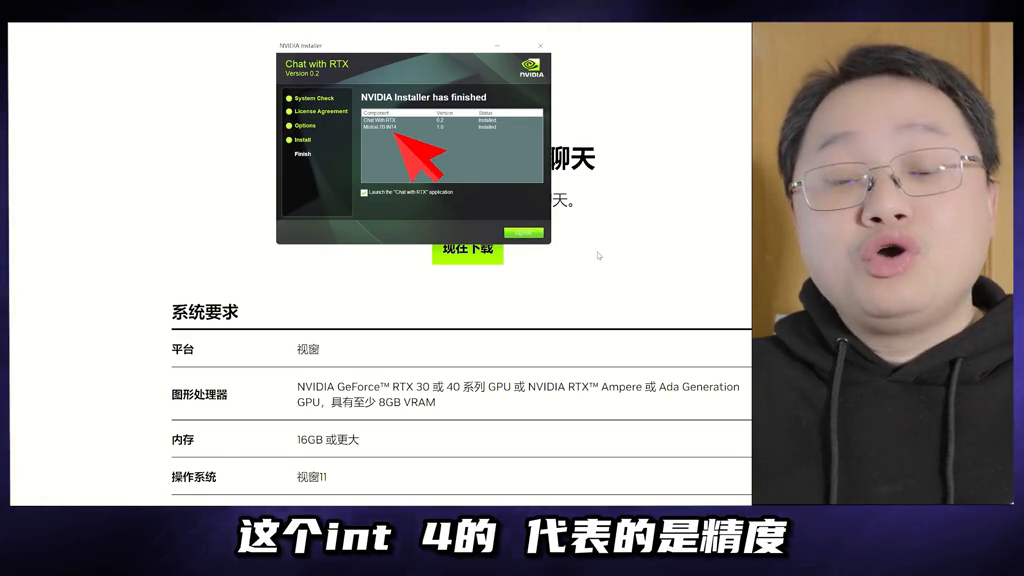
chatwithRTX安装好了,顺手下载安装了真正开源的大模型Mistral,不过是78量化压缩版本。int4代表的是精度,之前拆过大模型给大家看过,里面是一堆的参数,也就是浮点数,要在个人电脑上能跑起来,得压缩。将32位浮点数转为低精度的整数,int4就是4位的整数,这样就大大的减小了模型的大小,计算效率就提高了,反应速度就更快了,显然打折了生成质量,但是够用,因为它必须得这么干。
量化压缩大模型将这些技术平民化、傻瓜化,个人用户才能用的起来。
·安装完跳出命令窗口下载配置文件,跳出一个本地主机的链接,就是一个与大模型的交互窗口。
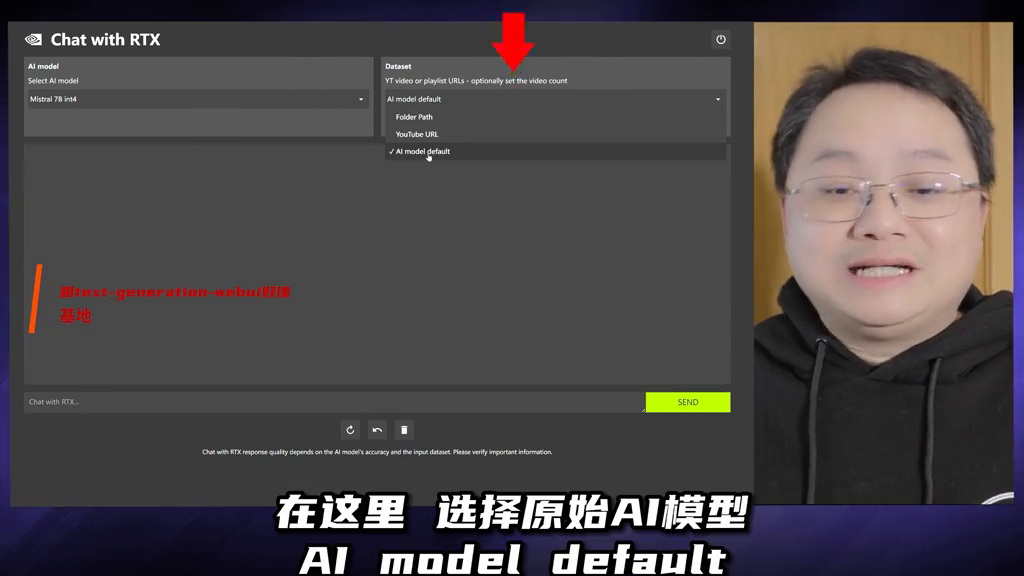
·在这里选择原始AI模型,就可以直接与下载的各种开源模型各种聊了,各种帮你写作、写脚本、改bug,各种换姿势折腾,随便你,反正不用投硬币。
·来看更良心的,这里选择文件夹路径,打开这个文件夹,可以把个人数据、各种txt、pdf、word文档放到这里面,它会吃掉消化掉,各种回答关于这些文件的问题,帮你读论文、读书、读材料。
·最强书童,点油管url,把油管粘贴进去,它会帮你转录好,吃完消化掉,然后各种问,这只是beta版本,英伟达一定肯定绝对会不断的强大这个工具,同时不断地的去帮各种开源大模型发展壮大。

他投了mistral,欧洲最强ai,最强开源,水平差不多是gpt3.5,很猛,很强。只有开源大模型足够强大,本地部署足够简单,才会有无数的个人来用这些开源的大模型,才在游戏卡、矿卡之后再现民间买卡用AI的浪潮。
他那攀岩的骨架那陡峭度,自己看着都慌。如果只靠几家巨头早晚摔碎,扶植开源大模型,推出本地傻瓜部署工具,英伟达直接把手伸向了openai的地盘。这两招至关重要,AI平民化之后,长尾的显卡需求才能去平衡巨头们的一时疯狂,几千万人的消费级市场比几个大客户睡觉安稳多了。

同理,有多少开工厂的没怒过,辛辛苦苦一年到头就是再给几个核心材料打工。openai也这么觉得,忙前忙后的在给老黄打工。CEO奥特曼神叨叨的说:我要融资7万亿美金自己造芯片,这是必然,谁不想往上游做材料,只是这7万1有点吓人。

美国GOP的10%听起来很疯狂,这是要干什么?回顾计算机的发展史,当年IBM为了将计算机商业化,开启了豪赌的360项目,研发投入50亿美元,要知道研制出原子弹的曼哈顿计划也才花了20亿2美元。openai要7万1到底要干什么?肯定不是现在看到的这些,一定是原子弹登月第一台计算机那样的工程。

我个人认为一定是量子芯片,量子AI,否则干什么?7万亿能买几个英伟达,买下台湾,买下天下所有的GPU,不敢量子芯片干什么?AI的觉醒肯定不靠英伟达这种GPU,堆满地球加月球都不行。
现在,只要你有一张英伟达显卡,你就能用上本地大模型,而且是用上最高的推理速度。
春节期间,英伟达悄悄官方发布了一款工具,chat with RTX.

安装这个,目前需要NVIDIA GeForce RTX 30 或 40 系列 GPU 或 NVIDIA RTX Ampere 或 Ada 代 GPU,至少 8GB 显存。

下载包非常庞大,有35G之大。
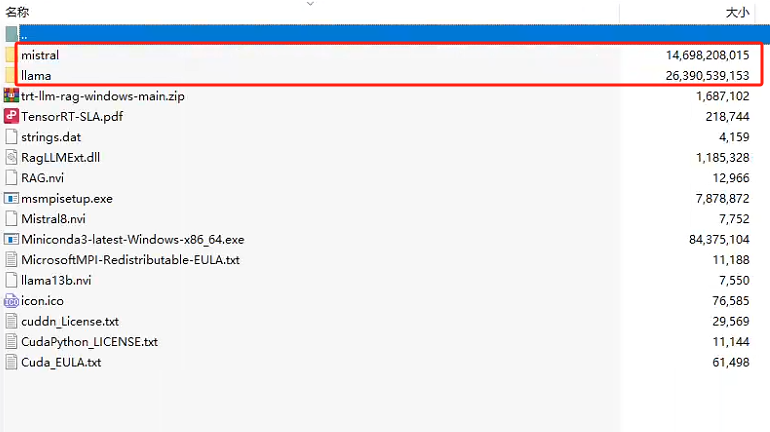
解压之后就会发现,那么庞大是因为内置了两个模型,llama2-13B和mistral-7B。这里提供的都是经过量化的版本。
在功能上,Chat with RTX 支持多种文件格式,包括文本、pdf、doc/docx 和 xml。只需将应用程序指向包含文件的文件夹,它就会在几秒钟内将它们加载到库中。此外,您可以提供 YouTube 播放列表的 URL,该应用程序将加载播放列表中视频的转录,使您能够查询它们涵盖的内容。
安装和正常安装程序一样,需要等待比较长的时间,之后点击桌面图标就可以启动。程序启动好了会弹出浏览器。
不过,大部分网上教程没有告诉你的是,这里面程序还会访问huggingface,这个全球最大的模型站目前处于不可访问状态,你需要一点魔法才能访问并正常启动。
启动好了是这个样子的:
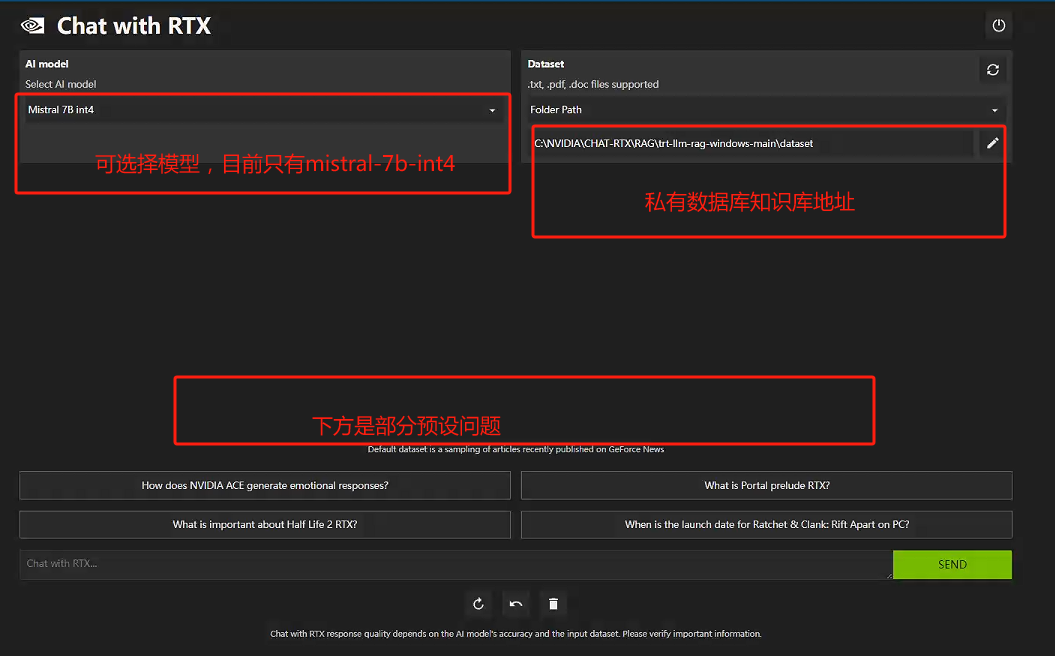
和其他本地大模型基于pytorch推理或者llama-cpp推理不同,chat with RTX的推理框架是业界最强的,毕竟是老黄家出品,发挥显卡最大效用是必须的。
在我的3090上,mistral的推理能够轻松跑到60token/s。速度毋庸置疑是极快的。
不过,它也有不小的缺点,最大的问题是,官方提供模型目前只有llama2-13B和mistral-7B。这两个模型比较老旧了,对中文支持也不好,因此对中国用户来说,意义不是很大。
而且由于架构不同,还不能直接用开源模型,需要另外转换一下量化;如果需要使用中文比较强的模型,需要英伟达后期改造或者由开源社区提供第三方支持。
其实,chat with RTX这套玩意早就在GitHub开源。它的另一个名字是 trt-llm-rag-windows。大家访问下面的网址开源获得更多信息:
https://github.com/NVIDIA/trt-llm-rag-windows
我们之前也介绍了其他本地大模型工具。有兴趣可以参考。它们的硬件要求甚至可以低至无需显卡。
英伟达推出了自家版本的ChatGPT,名字很有GPU的味道——
Chat With RTX。
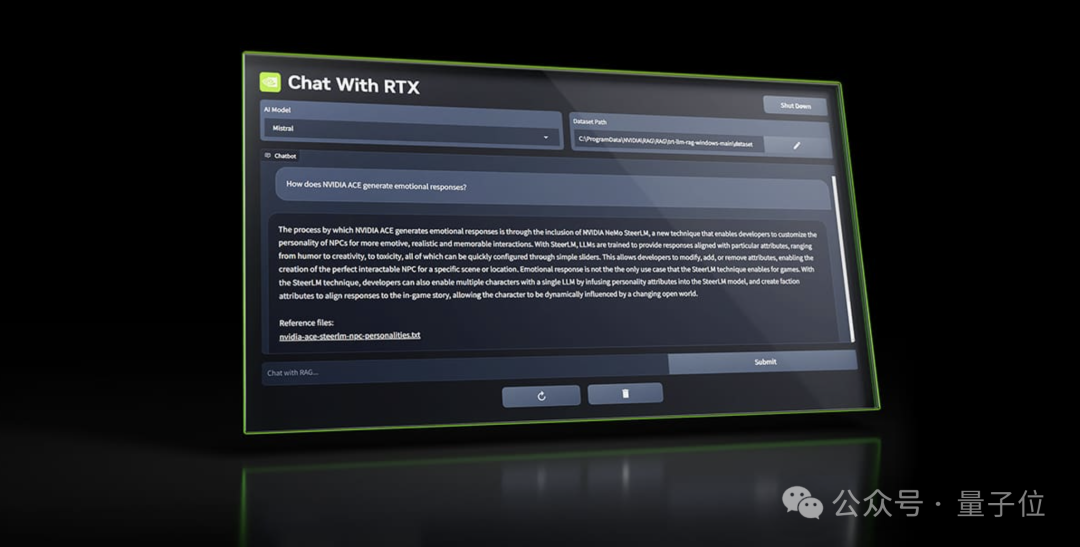
英伟达的这款AI聊天机器人和目前主流的“选手”有所不同。
它并非是在网页或APP中运行,而是需要下载安装到个人电脑中。
这波操作,不仅是在运行效果上会更快,也就意味着Chat With RTX在聊天内容上或许并没有那么多限制。
网友们也纷纷对这一点发出了感慨:
哇~这是本地运行的耶~
当然,在配置方面也是要求的,只需要至少8GB的RTX 30或40系列显卡即可 。
。
那么Chat With RTX的实际效果如何,我们继续往下看。
英伟达版ChatGPT
首先,值得一提的是,Chat With RTX并非是英伟达自己搞了个大语言模型(LLM)。
它背后所依靠的仍是两款开源LLM,即Mistral和Llama 2,用户在运行的时候可以根据喜好自行选择。
Pick完LLM之后,就可以在Chat With RTX中上传本地文件。
支持的文件类型包括txt,.pdf,.doc/.docx和.xml。
然后就可以开始提问了,例如:
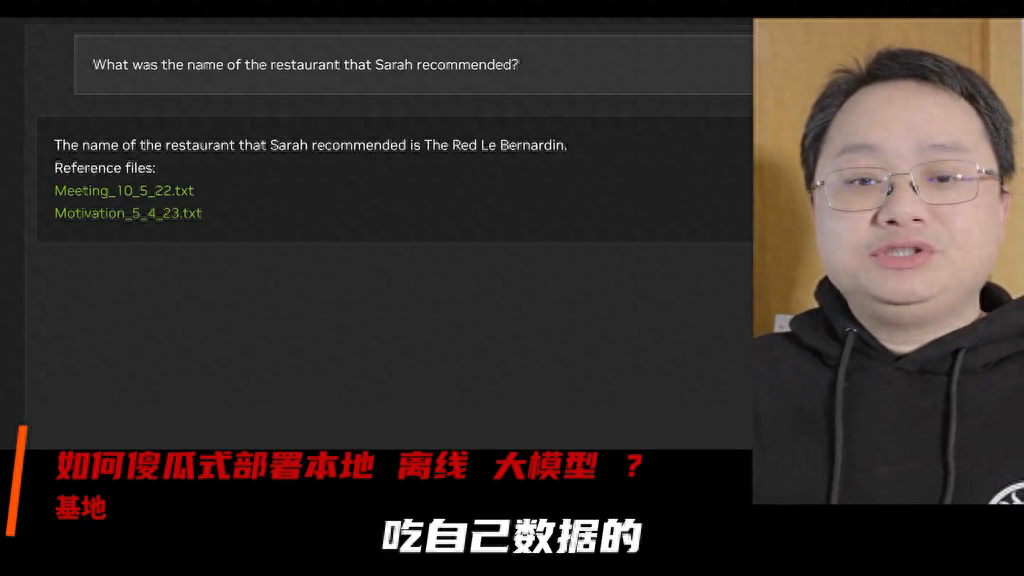
Sarah推荐的餐厅名字是什么?
由于是在本地运行,因此Chat With RTX生成答案的速度是极快的,真真儿的是“啪的一下”:
Sarah推荐的餐厅名字叫做The Red Le Bernardin。
除此之外,Chat With RTX另一个亮点功能,就是可以根据在线视频做回答。
例如把一个油管视频的链接“投喂”给它:
然后向Chat With RTX提问:
英伟达在CES 2024上宣布了什么?
Chat With RTX也会以极快的速度根据视频内容作答。
至于其背后用到的技术方面,英伟达官方只是简单提了一句:“用到了检索增强生成 (RAG)、NVIDIA TensorRTLLM软件和NVIDIA RTX等。”
如何食用?
正如我们刚才提到的,Chat With RTX的用法很简单,只需一个下载安装的动作。
不过在配置上,除了GPU的要求之外,还有一些条件,例如:
系统:Windows 10或Windows 11
RAM:至少16GB
驱动:535.11版本或更新
不过Chat With RTX在大小上并没有很轻量,共计大约35G。
因此在下载它之前,务必需要检查一下Chat With RTX所需要的安装条件。
不然就会出现各种各样的悲剧了:
不过实测被吐槽
The Verge在英伟达发布Chat With RTX之后,立即展开了一波实测。
不过结论却是大跌眼镜。
例如刚才提到的搜索视频功能,在实际测试过程中,它竟然下载了完全不同视频的文字记录。
其次,如果给Chat With RTX“投喂”过多的文件,例如让Chat with RTX为25000个文档编制索引,它就直接“罢工”崩溃了。
以及它也“记不住”上下文,因此后续问题不能基于上一个问题。
最后还有个槽点,就是下载Chat with RTX消耗了测试人员整整半个小时……
不过槽点之外,The Verge也比较中立地肯定了Chat with RTX的优点。
例如搜索电脑上的文档,其速度和精准度是真香。
并且做总结也是Chat with RTX较为擅长的内容:
更重要的是,在本地运行这样的机制,给用户文件的安全性带来了保障。
那么你会pick英伟达版的ChatGPT吗?
分享一个国内免费使用GPT4.0的AI智能问答工具:智答专家。支持AI文本、作图、语音、Sora视频。无需魔法,亲测有效,点击访问
标签:ChatGPT,Chat With RTX,英伟达,NVIDIA
来源:智答专家
发布时间:2024-02-28 18:10

